
Cloud Data Fusion の Wrangler を使って文字コード変換してみた
この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので、ご注意ください。
こんにちは!エノカワです。
Google Cloud の データ統合サービスである Cloud Data Fusion は、 データパイプラインを迅速に構築・管理するためのフルマネージドなサービスです。
前回、Cloud Data Fusion で外部データをBigQueryテーブルに投入することを試してみたのですが、 必要なノードを配置して接続してプロパティを設定して、、という作業をGUI上で完結してできるので、 手軽にデータパイプランを作成することができました。
BigQueryテーブルのデータ取り込み
ところで、BigQueryテーブルのデータ取り込みの形式は、UTF-8 のエンコードをサポートします。
(CSV ファイルの場合のみ、フラットデータについて ISO-8859-1 エンコードもサポート)
では、文字コードが UTF-8 以外のデータをBigQueryテーブルに取り込む場合、Cloud Data Fusion ではどのようにパイプラインを構成すればよいのでしょうか?
そこで今回は、Cloud Data Fusion で文字コードを変換してBigQueryテーブルする際に試したことをご紹介します。
作成するパイプライン
いきなり結論になりますが、文字コード変換にはWranglerノードを使用しました。
作成したパイプラインは以下です。

GCSノードでデータを取得し、Wranglerノードで文字コード変換、CSV ParseノードでCSVパースを行い、BigQueryノードでBigQueryテーブルにデータを取り込みます。
データ準備
BigQueryテーブルに取り込むデータファイルを準備します。
以下のサイトでCSV形式のデータファイルを作成しました。
ヘッダーなしのシンプルでスモールな名簿データです。
※実在の人物やメールアドレスとは一切関連ございません。
7361,山県 勇次,SDY4APj6@sample.co.jp 844,早田 年紀,q3uOWln0B3@sample.jp 7876,真壁 雅信,WxP0tq@sample.net 5069,高坂 良彦,Wy006FsFTy@test.net 5695,丹治 陽向,mRtoZYgYwl@sample.co.jp 8112,西口 敦盛,e11Rzz5QM@test.org 6416,安村 澄子,wbc35@test.org 9289,仲 三夫,E_3pv@example.com 354,大西 晴菜,sFWPKMr@example.com 9312,武井 灯,hlhfXl0vv@test.net
作成したCSVファイルは、任意のGCSバケットにアップロードしておきます。
インスタンス作成
何はともあれ Cloud Data Fusion インスタンスを作成します。

具体的な作成手順は今回は割愛します。
インスタンス作成、パイプライン構築、デプロイなど Cloud Data Fusion の基本的な操作については、下記エントリで紹介しておりますので、こちらもご参照ください!
パイプライン作成(文字コード変換なし)
まずは文字コード UTF-8 のデータをBigQueryテーブルにロードしてみましょう。
UTF-8 のエンコードはサポートされているので、文字コード変換は不要です。
GCS Source ノード設定
画面左のSourceからGCSを選択して Pipeline Studio に配置します。

GCSノードのPropertiesをクリックして、プロパティ画面を開きます。

GCS設定
識別名、GCSパス、フォーマットを入力します。
- Reference Name
GCS - Path
gs://fusion_training_bucket/generated.csv
※GCSにアップロードしたCSVファイルを指定 - Format
csvを選択
出力データ構造
Output Schemaに出力データ構造を入力します。
CSVファイルの値をもとにフィールド名、フィールド型を指定します。
ここで指定したデータ構造が後続のノードに渡されます。

BigQuery Sink ノード設定
次にBigQueryノードを設定します。
画面左のSinkからBigQueryを選択して、 Pipeline Studio に配置します。
GCSノードから矢印を引っ張ってBigQueryノードに接続します。

BigQueryノードのPropertiesをクリックして、プロパティ画面を開きます。

BigQueryテーブル設定
識別名、データセット名、テーブル名を入力します。
- Reference Name
BigQuery - Dataset
fusion_training_dataset - Table
generated_csv
プレビュー実行
パイプライン構築が完了したので、正しく動作するかプレビュー実行してみましょう。
画面右上のPreviewをクリックしてプレビューモードにしてから、Runをクリックします。

しばらくすると、プレビュー実行が成功したメッセージが表示されます。
BigQueryノードのPreview Dataをクリックすると、 データを見ることができます。
正しくデータが渡ってきていることが分かります。

パイプライン作成(文字コード変換あり)
ここからが本題です。
文字コード UTF-8 以外のデータをBigQueryテーブルに取り込んでみましょう。
今回は文字コード UTF-16 のデータを試してみます。
下記コマンドにより、作成したCSVファイルを UTF-16 の変換しました。
$ iconv -f UTF-8 -t UTF-16 generated.csv > generated_utf16.csv
先ほどと同様、CSVファイルを任意のGCSバケットにアップロードしておきます。
実は、GCSノードにはファイルの文字コードを指定するプロパティFile encodingがあります。

プルダウンから選択するのですが、残念ながらリストの中に UTF-16 はありません。。

そこで今回は、WranglerノードとCSV Parseノードを使用します。
画面左のTransformからWranglerと*CSV Parser**を選択して、 Pipeline Studio に配置します。
GCS、Wrangler、CSV Parser、BigQueryの順にノードを接続します。

GCS Source ノード設定
GCSノードのPropertiesをクリックして、プロパティ画面を開きます。

GCS設定
GCSパス、フォーマットを以下のように変更します。
- Path
gs://fusion_training_bucket/generated_utf16.csv
※UTF-16 に変換したCSVファイルを指定 - Format
blobを選択
ここでポイントとなるのが、Formatのblob指定です。
ファイル自体はCSV形式なのですが、後続のWranglerノードで文字コード変換を行うため、ここではバイナリ形式としてロードします。
出力データ構造
データ構造が変わるため、Output Schemaにも変更します。
ロードしたバイナリをbodyフィールドにbyte型で受ける形にします。

Wrangler Transform ノード設定
続いて、Wranglerノードで文字コード変換の設定を行います。
WranglerノードのPropertiesをクリックして、プロパティ画面を開きます。

Wrangler設定
入力フィールド名、前提条件、レシピを入力します。
- Input field name
*
※すべてのフィールド(body)が変換対象 - Precondition
false
※前提条件なし(フィルターしない) - Directives (Recipe)
set-charset :body 'UTF-16'
Wranglerノードでは、データのクレンジングや変換などを行うことができますが、その一連の処理をRecipeとして定義します。
今回は文字コード変換を行いたいので、set-charsetというディレクティブにUTF-16を指定しています。
set-charset ディレクティブは、現在のデータのエンコードを設定し、それを UTF-8 文字列に変換します。
出力データ構造
Output Schemaに出力データ構造を入力します。
byte型のbodyを文字コード変換して文字列型にしたので、string型にします。

CSV Parser Transform ノード設定
CSV ParserノードでCSVレコードとしてパースします。
CSV ParserノードのPropertiesをクリックして、プロパティ画面を開きます。

CSV Parser設定
入力フィールド名、フォーマットを選択します。
- Input field to Parse
body
※すべてのフィールド(body)が変換対象 - Formats
DEFAULT
Formatsには、パースするレコードの形式を選択できます。
Tab Delimitedを選択すると、TSVレコードをパースすることができます。
今回は、CSV形式なのでDEFAULTを選択しています。
出力データ構造
Output Schemaに出力データ構造を入力します。
CSVレコードにパースした後のデータ構造を指定します。
このデータ構造が後続のノードに渡されます。

プレビュー実行
パイプライン変更が完了したので、プレビュー実行してデータを見てみましょう。
Wranglerノードのデータを見てみると、文字コード変換されていることが分かります。

CSV Parserノードのデータを見てみると、CSVレコードとしてパースされていることが分かります。

パイプライン実行
プレビュー実行で想定通り文字コード変換されていることが確認できたので、デプロイして実際に動かしてみましょう。
Pipeline Studio 右上のDeployをクリックして、しばらくするとデプロイが完了します。
Runをクリックして、パイプラインを実行します。

数分後、画面上部のStatusにSucceededと表示されました。
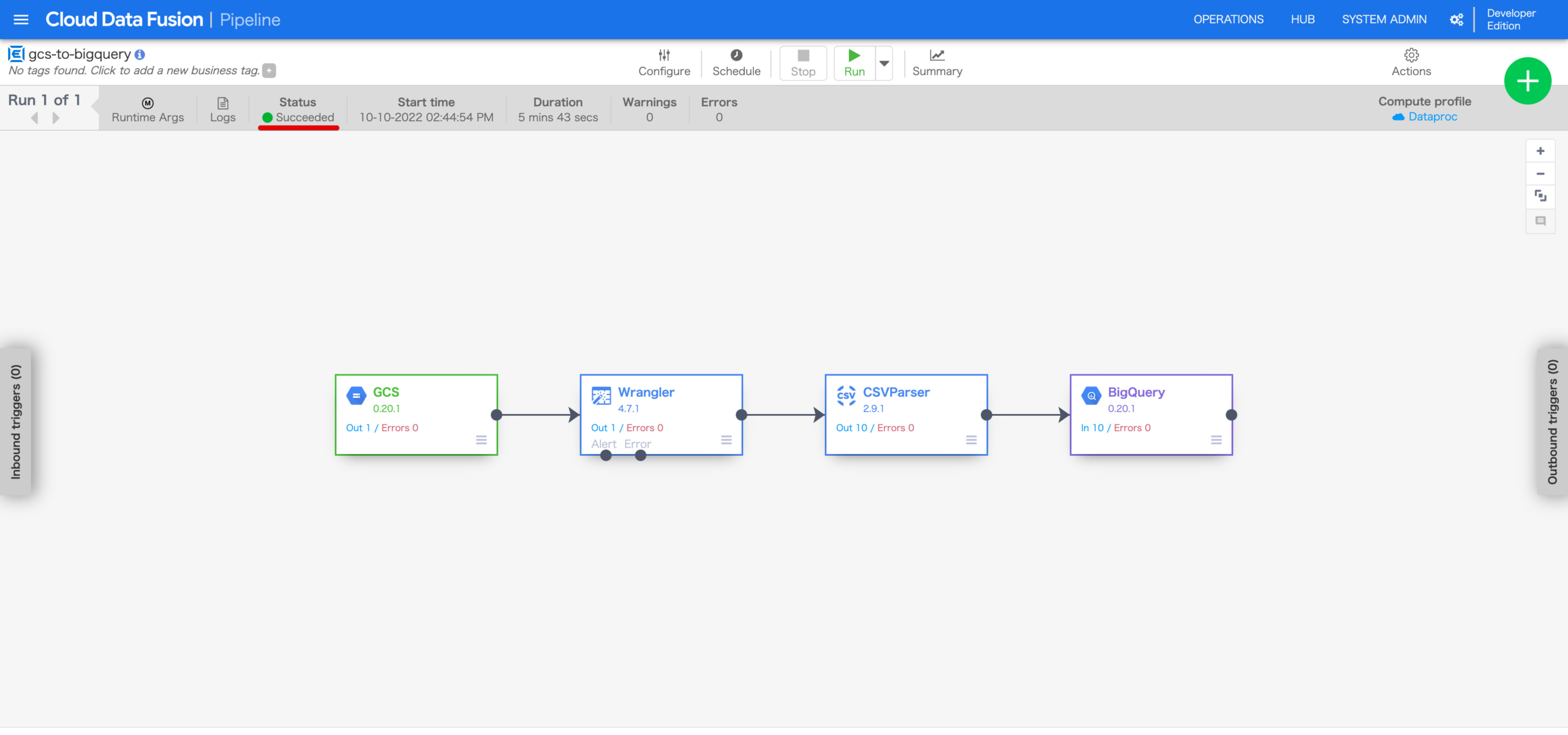
パイプラインの実行が正常に完了したようです。
データ確認
最後に、BigQueryテーブルにデータが投入されたか確認してみましょう。
fusion_training_datasetデータセットの下にgenerated_csvテーブルが作成されていました。
BigQueryノードのデータ構造に従ってテーブルスキーマが定義されています。

プレビューでデータを確認すると、データが投入されていました!

まとめ
以上、Cloud Data Fusion の Wrangler ノードを使用することで、文字コード UTF-16 のCSVファイルを UTF-8 に変換してBigQueryテーブルに取り込むことができました。
当初、GCSノードでファイルの文字コードを指定するプロパティFile encodingがあるので、それで何とかなるやと思っていたのですが、リストに UTF-16 が無かったので別の方法を模索していたところ、Wranglerノードを使用して文字コード変換するに至りました。
ちなみに、文字コードは UTF-16 以外にWindows-31J(こちらもFile encodingのリストにはない)もset-charsetディレクティブで変換することができました。
また、今回はCSVパース処理をCSV Parserノードで行いましたが、Wranglerノードでparse-as-csvディレクティブを使用することで同様の処理を行うことができます。
Wranglerノードは文字コード変換以外にも他もフィールド型変換やフィルタリングなど様々なディレクティブが用意されているので、これらを組み合わせることで柔軟なデータ変換処理が行えそうです。
これから色々と試してみたいと思います!
参考
- データの読み込みの概要 | BigQuery | Google Cloud
- Cloud Data Fusion のプラグイン リファレンス | Google Cloud
- Google Cloud Storage File Reader Batch Source - CDAP Documentation - Confluence
- Wrangler Transformation - CDAP Documentation - Confluence
- Set Charset directive - CDAP Documentation - Confluence
- CSV Parser Transformation - CDAP Documentation - Confluence
- Google BigQuery Table Sink - CDAP Documentation - Confluence
- Parse as CSV directive - CDAP Documentation - Confluence
- Directives - CDAP Documentation - Confluence










